2026年のGoogle Workspace向けAIツール5選(比較・ランキング)
2026年のGoogle Workspaceユーザー向けに、GPT Workspace、Gemini、Jasper、GPT for Sheets、Copy.aiの5つの最高のAIツールをテストし、ランク付けしました。あなたのワークフローに合うものを確認してください。
Google Workspaceと連携すると主張するAIツールの数は大幅に増加しましたが、そのほとんどは、Workspaceとの統合が薄い汎用アシスタントか、一つの特定の問題しか解決しないニッチなツールです。選択肢を評価するために時間を費やしたことがある方なら、「Google Docsで動作する」という言葉がツールによって全く異なる意味を持つことに気づいたかもしれません。
このランキングは、2026年のGoogle Workspace向け最高のAIツール——Google WorkspaceユーザーがDocs、Sheets、Slides、Gmail、Driveで実際に時間を費やすアプリの中で真の価値を提供するツール——に焦点を当てています。汎用AIアシスタントを比較しているのではありません。ワークフローとの統合の深さ、出力品質の改善度、コストが正当化されるかどうかでツールを比較しています。
これらのAIツールをどう評価したか
各ツールを5つの次元で評価しました:
統合の深さ — Google Workspaceアプリ内でどれほどネイティブに動作するか?タブの切り替えが必要か、それともDocs、Gmail、Sheetsの内部で直接動作するか?
出力品質 — ライティング、分析、メール作成、コンテンツ制作などの実際の作業タスクに対して、実際のAI出力はどれほど良いか?
モデルの柔軟性 — タスクごとに異なるAIモデルにアクセスできるか、それとも単一のオプションに縛られているか?
チームでの使いやすさ — 共有設定、プロンプト、管理者コントロールを持つチーム全体に展開できるか?
コストパフォーマンス — 実際に得られるものを考えると、価格は合理的か?
各ツールは同じタスクセットでテストされました:Google Docsで500語のクライアント提案書を作成し、Sheetsで収益分析の数式を構築し、GmailでフォローアップメールEを書き、Slidesでプレゼンテーションのアウトラインを生成。
#1 GPT Workspace — ChatGPTパワーユーザーに最適

最適用途: 最も有能なAIモデルをGoogle Workspaceに深く統合したいチーム。
GPT Workspaceがトップに立つのは、このリストの他の何よりもE最も重要なことをうまくやっているからです:ワークフローを変えることなく、すでに使用しているGoogle Appsに直接優れたAIを組み込みます。
Chrome拡張機能とGoogle Workspace Add-onは数分でインストールでき、Google Docs、Sheets、Slides、GmailでサイドバーEを即座に有効化します。そのサイドバーから、GPT-4o、GPT-4.5、o1、o3——OpenAIの最も有能なモデル——にアクセスでき、タスクの要件に応じてそれらを切り替えることができます。高速なコンテンツ作成?GPT-4o。複雑な推論やデータ分析?o1またはo3。この柔軟性は、単一モデルに縛り付けるツールに対する真の優位性です。
際立つ点:
Docsでは、ライティングアシスタンスはGoogle エコシステムで入手できる最高のものです。長文コンテンツ、繊細な書き直し、提案書、レポートは、同じプロンプトに対してGeminiが生成するものよりも明確でE自然に仕上がります。この違いは、品質が重要な対外向けコンテンツで最も顕著です。
Sheetsでは、GPT Workspaceは複雑な数式ロジック——多条件QUERYfunctions、ARRAYFORMULAパイプライン、データ変換タスク——を競合他社よりE信頼性高く処理します。平易な英語による分析リクエストは、簡略化された近似値ではなく、動作する出力を生成します。
Gmailでは、重要なメール(アウトリーチ、提案、困難な会話)の作成品質は、GoogleのE組み込み提案よりも明らかに優れています。
プロンプトライブラリ機能は過小評価されています。チームは最もE一般的なタスク——標準メール形式、レポートテンプレート、分析フレームワーク——のE共有プロンプトライブラリを構築でき、チームの全員が同じ出発点を使用します。これによりAI出力のばらつきが減り、ゼロからプロンプトを書きたくない人の作業が速くなります。
管理者コントロール、使用状況の追跡、Google管理コンソールを通じたチーム展開により、個人のパワーユーザーだけでなく、組織にとっての実用的な選択肢となっています。
制限: GeminiのクロスアプリコンテキストはありませE——GoogleのネイティブAIと同じようにECalendarから引き出したり、Drive全体を検索したりすることはできません。そのような組織的インテリジェンスを必要とするタスクには、Geminiが依然として優れたツールです。
価格: 無料ティアあり。有料プランはgpt.space/pricingを参照。Google WorkspaceチームにとってMicrosoft Copilotよりもかなり手頃です。
Copilotとの直接比較については、GPT Workspace vs Microsoft Copilotを参照してください。
#2 Google Gemini — 最高のネイティブソリューション
最適用途: 追加インストールなしにAIを使いたいユーザーと、クロスアプリコンテキストの恩恵を受けるワークフロー。
Business StandardE以上のWorkspaceプランを使用しているなら、GeminiはすでにGoogle Appsにあります。そのアクセスのしやすさ——ゼロセットアップ、拡張機能なし、追加コストなし——は、ほとんどのGoogle Workspaceユーザーのデフォルトの出発点となっています。
Geminiのコア機能は広い範囲をカバーします。Gmailでは、スレッドの要約と作成アシスタンスが日常的なメール作業の大部分を処理します。Docsでは、「書くのを手伝ってください」機能が使用可能な初稿を生成し、長いドキュメントを要約します。Sheetsでは、平易な英語からの数式アシスタンスが標準タスクに確実に機能します。Meetでは、Geminiが会議を自動的にトランスクリプトして要約します。
このリストの他のすべてのツールに対してGeminiが持つ真の優位性は、クロスアプリコンテキストです。GoogleがAIと基盤となるWorkspaceデータの両方を制御しているため、GeminiはDrive、メール、カレンダーを一緒に見て、ソース間で情報を繋げることを必要とする質問に答えることができます。サードパーティのツールでこれを複製するものはありません。
制限: 長文の対外向けコンテンツの出力品質はGPT-4oとGPT-4.5に遅れをとります。モデル間で選択することはできません——Geminiになります。プロンプトライブラリとカスタマイズオプションはGPT Workspaceほど開発されていません。SheetsでのE複雑な数式作業は、OpenAIの推論モデルを使用するほど信頼性が高くありません。
価格: Google Workspace Business Standard(月額$14/ユーザー)以上に含まれます。Gemini Advanced(最も有能なモデルティア)は、月額$19.99のGoogle One AI Premiumサブスクリプションが別途必要です。
GPT WorkspaceとGeminiがどのように補完し合うかの完全な詳細については、GPT Workspace vs Google Workspace向けGeminiを参照してください。
#3 Jasper — マーケティングチームに最適
最適用途: ブランドの一貫性を保ちながら大量のコンテンツを制作するマーケティングチーム。
Jasperはエンタープライズグレードのライティングプラットフォームとして自らを位置づけており、特定のオーディエンス——ブランドボイスの一貫性を維持しながら大量のコンテンツを制作する必要があるマーケティングチーム——にとってその位置づけを確立しています。
Jasperが独自にうまくやっていることはブランドボイス管理です。ブランドの既存のコンテンツ——ブログ投稿、マーケティングコピー、メールキャンペーン——でJasperをトレーニングでき、生成するすべてのものにそのスタイルを一貫して適用します。確立されたブランドガイドラインを持つ組織にとって、これにより編集のオーバーヘッドが大幅に削減されます。
Jasperはまた、マーケティング特有のテンプレートの大きなライブラリも提供しています:広告コピー、ランディングページのコピー、メールシーケンス、ソーシャルメディア投稿、製品説明。これらの形式を定期的に制作する作業が含まれている場合、Jasperのテンプレートは汎用AIツールでは節約できない時間を節約します。
Google Workspace統合: JasperはそのエディターをDocsに持ち込むGoogle Docs アドオンを持っており、1年前よりもWorkspaceユーザーにとって実用的です。ただし、統合はSheets、Slides、またはGmailに意味のある形では拡張されていません。コンテンツ以外のワークフローでは、Jasperは役立ちません。
制限: ここの他のツールと比べて高価(スターターで月額$49、プロで月額$125)。Google Workspace統合はDocsに限定されています。マーケティングコンテンツを大量に制作しないチームには過剰であり、非マーケティングタスクの一般的な書き込み品質はGPT Workspaceより明らかに優れていません。
価格: スターターで月額$49/ユーザー、プロで月額$125/ユーザー。カスタム価格のビジネスプランも利用可能。
#4 GPT for Sheets and Docs — スプレッドシート専用数式ツール
最適用途: 主にSheetsでAIアシスタンスが必要で、フルプラットフォームに支払いたくないユーザー。
GPT for Sheets and Docsは、Google SheetsとDocsの内部に直接カスタムGPT関数を公開する軽量のGoogle Workspace Add-onです。スプレッドシートセル内で直接=GPT("このテキストを要約して", A1)のような関数を呼び出すことで使用します——サイドバーは不要です。
Sheetsで大部分の時間を過ごし、大規模なデータ処理にAIが必要なユーザー——回答の分類、テキストフィールドからの情報抽出、エントリの一括要約——にとって、このツールは非常に効率的です。チャットインターフェースにデータを手動でコピーすることなく、数千行にわたってGPT関数を実行できます。
得意なこと: SheetsでのE一括テキスト処理が際立ったユースケースです。調査回答の分析、顧客フィードバックの分類、非構造化テキストからのエンティティ抽出、セルの翻訳——これらすべてはサイドバーツールよりも関数ベースのAIの方が速く実用的です。
制限: ライティングアシスタントではありません。サイドバーなし、会話インターフェースなし、メール統合なし。Google Docsでは、機能はSheets機能よりも限定的です。データ中心のユースケース以外のEものには、GPT WorkspaceまたはGeminiの方が適切です。
価格: 使用量限定の無料ティア。有料プランは月額約$19から。フルプラットフォームよりもかなり安く、それが要点です。
#5 Copy.ai — クイックコンテンツに最適
最適用途: 高速で使用可能なコンテンツ出力が必要で、Google Workspaceのワークフローに深く投資していないユーザー。
Copy.aiはそのウェブアプリにGoogle Docs統合を追加した汎用AIライティングツールです。速さに重点を置いています:必要なものを説明すると、複数のバリエーションを素早く生成し、最良のものを選びます。
このツールは短いコンテンツに適しています——製品説明、広告コピー、ソーシャル投稿、メールの件名、1段落の要約。複数バリエーションのアプローチは、どのトーンや角度が欲しいか不確かで、決める前にオプションを見たい場合に便利です。
Google Workspace統合: Copy.aiのDocs統合は機能的ですが深くありません。ネイティブサイドバーではなく、Docsからアクセスできるコピー.aiウェブアプリへのウィンドウです。ここではSheets、Slides、またはGmailの統合は見つかりません。
制限: GPT WorkspaceやJasperと比べてGoogle Workspace統合が浅いです。Workspaceアプリで1日のほとんどを過ごすユーザーには、Copy.aiのアプローチは一つではなく二つの場所で作業しているように感じられます。より長く複雑なコンテンツの出力品質は不安定です。
価格: 無料ティアあり。プロは月額$49。追加機能とシートを持つチームプランも利用可能。
比較表
| ツール | Google Apps統合 | 最良のユースケース | モデル選択 | 無料ティア | 開始価格 |
|---|---|---|---|---|---|
| GPT Workspace | Docs, Sheets, Slides, Gmail | パワーユーザー、チーム | GPT-4o, o1, o3 | あり | 料金ページを参照 |
| Google Gemini | Docs, Sheets, Slides, Gmail, Meet | ネイティブ/インストール不要 | Geminiのみ | Workspaceプランで利用可能 | Workspaceに含まれる |
| Jasper | Docsのみ | マーケティングコンテンツ | GPT-4ベース | なし | $49/ユーザー/月 |
| GPT for Sheets/Docs | Sheets, Docs | バッチデータ処理 | GPT-4 | あり | 約$19/月 |
| Copy.ai | Docs(限定) | クイックショートコピー | GPT-4ベース | あり | $49/月 |
どのツールを選ぶべきか?
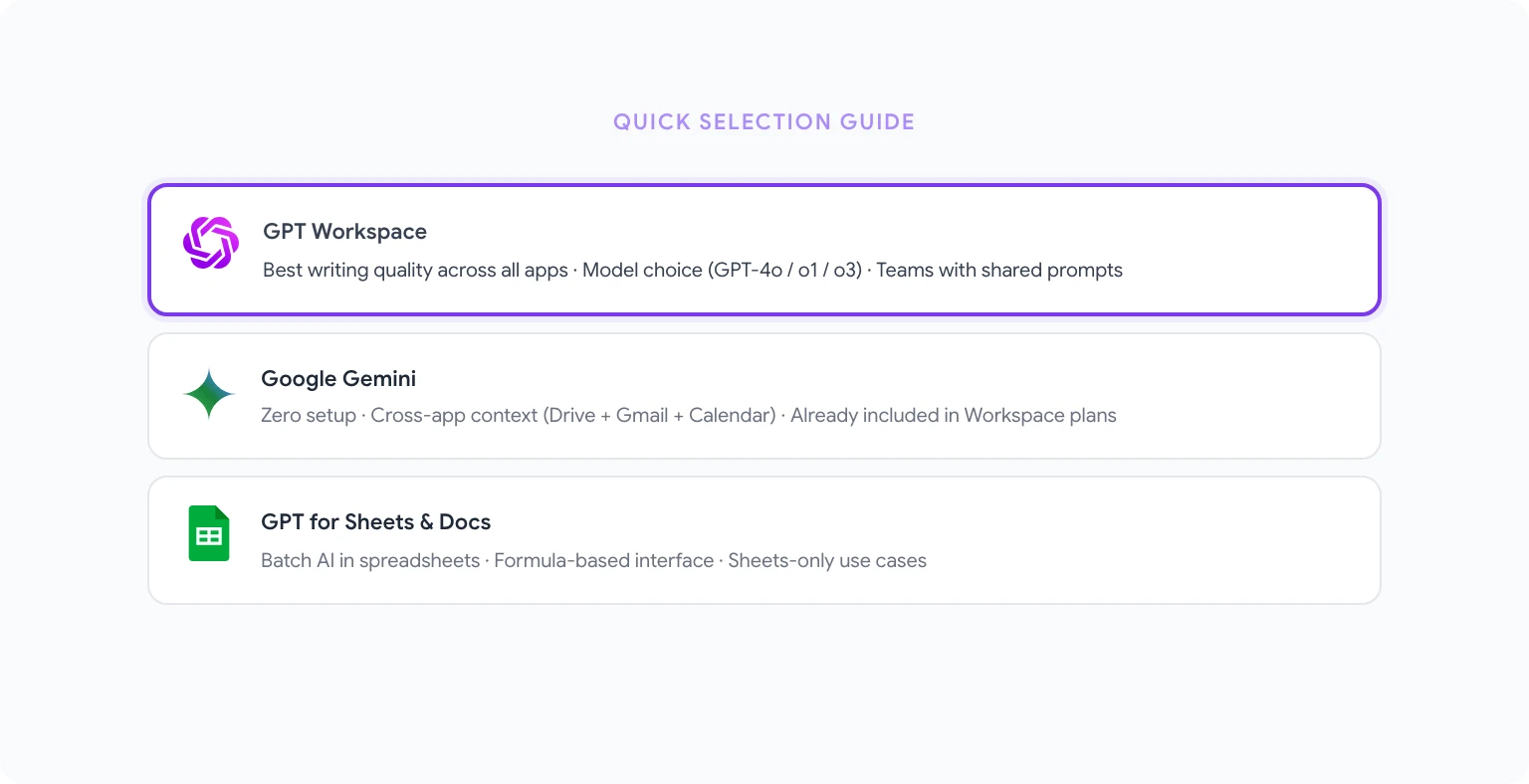
すべてのGoogle Appsで最高のAIライティングと複雑なタスクが必要な場合: GPT Workspaceが明確な選択です。Docs、Sheets、Slides、GmailにわたるEモデルの品質、統合の深さ、各タスクに適切なモデルを選択する柔軟性が、真剣なWorkspaceユーザーにとって最も有能なオプションとなっています。
ゼロセットアップとクロスアプリコンテキストが必要な場合: Geminiはすでにそこにあり、クイックタスク、要約、メール・カレンダー・Driveを繋げることで利益を得るものすべてに優れています。
大量のコンテンツを制作するマーケティングチームを運営している場合: JasperのブランドボイスE管理とテンプレートライブラリは、規模でのコストに見合います。そうでなければ過剰です。
Sheetsで大量のデータを処理する場合: GPT for Sheets and Docsはスプレッドシートでのバッチ AI処理に最も効率的なツールで、価格も適切です。
プラットフォームにコミットせずに高速で多様なコンテンツオプションが必要な場合: Copy.aiは短いコンテンツに高速で柔軟です。
ほとんどのGoogle Workspaceユーザーにとって、最も実用的なセットアップは品質が重要なタスクにはGPT Workspace、クイックな日常作業にはGeminiのネイティブ機能を組み合わせることです。2つのツールは競合せず、互いを補完します——そして合わせると、どちらか一方よりもワークフローのより多くをカバーします。
よくある質問
Google Workspaceで複数のAIツールを同時に使用できますか? はい。GPT Workspace(Chrome拡張機能またはAdd-on)とGeminiは同じGoogle Appsで共存します。両方を有効にしても競合は発生しません。タスクに応じてどちらを使用するかを選択します。
GPT WorkspaceはGeminiを置き換えますか? いいえ。GPT WorkspaceはGeminiにはない機能(特にモデル選択と複雑なライティングタスクの出力品質)を追加しますが、GeminiのクロスアプリコンテキストとネイティブE統合には、GPT Workspaceが複製できない利点があります。両方を一緒に使用することは、どちらか一方を選ぶよりも優れています。
Google Workspaceの20人のマーケティングチームに最適なツールは? GPT Workspace。チーム展開オプション、共有プロンプトライブラリ、Docs と Gmailにわたる一貫した出力品質のため。コンテンツ量とブランドの一貫性が主な懸念事項であれば、Jasperがオプションです。
何も支払わずにGoogle DocsでAIを無料で利用する方法はありますか? GeminiはBusiness Standard以上のプランに含まれています。GPT Workspaceには無料ティアがあります。GPT for Sheets and Docsにも無料ティアがあります。有料プランにコミットする前に選択肢があります。
GPT Workspaceを始めるにはどうすればいいですか? GPT Workspaceの完全なインストールガイドを参照してください。セットアップには約2分かかります。セットアップ後に使用する最良のプロンプトを探求したい場合は、Google Workspace向けベストChatGPTプロンプトが次に読む良い記事です。

